Flow Matching for Probabilistic Monocular 3D Human Pose Estimation
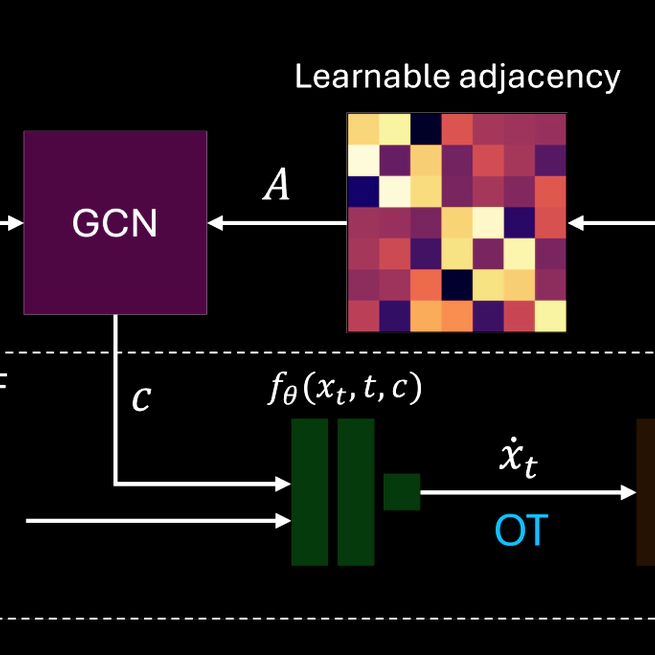
Recovering 3D human poses from a monocular camera view is a highly ill-posed problem due to the depth ambiguity. Earlier studies on 3D human pose lifting from 2D often contain incorrect-yet-overconfident 3D estimations. To mitigate the problem, emerging probabilistic approaches treat the 3D estimations as a distribution, taking into account the uncertainty measurement of the poses. Falling in a similar category, we proposed FMPose, a probabilistic 3D human pose estimation method based on the flow matching generative approach. Conditioned on the 2D cues, the flow matching scheme learns the optimal transport from a simple source distribution to the plausible 3D human pose distribution via continuous normalizing flows. The 2D lifting condition is modeled via graph convolutional networks, leveraging the learnable connections between human body joints as the graph structure for feature aggregation. Compared to diffusion-based methods, the FMPose with optimal transport produces faster and more accurate 3D pose generations. Experimental results show major improvements of our FMPose over current state-of-the-art methods on three common benchmarks for 3D human pose estimation, namely Human3.6M, MPI-INF-3DHP and 3DPW.
Jan 23, 2026
On the Role of Rotation Equivariance in Monocular 3D Human Pose Estimation
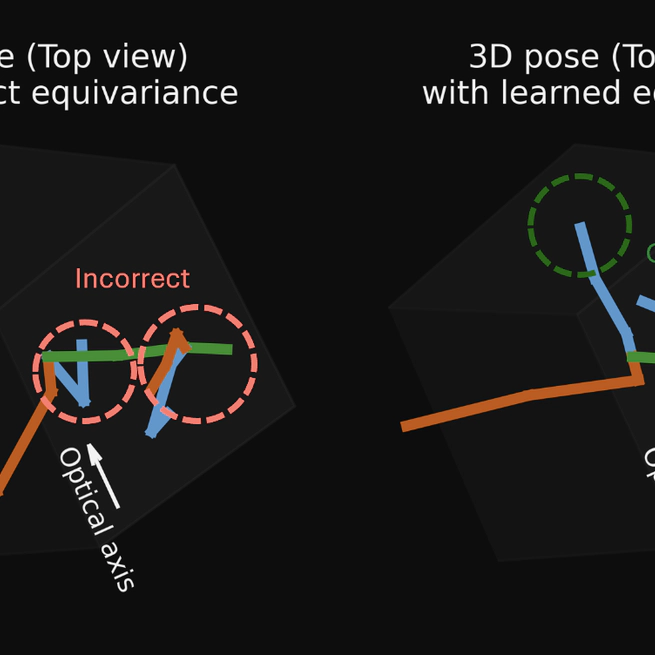
Estimating 3D from 2D is one of the central tasks in computer vision. In this work, we consider the monocular setting, i.e. single-view input, for 3D human pose estimation (HPE). Here, the task is to predict a 3D point set of human skeletal joints from a single 2D input image. While by definition this is an ill-posed problem, recent work has presented methods that solve it with up to several-centimetre error. Typically, these methods employ a two-step approach, where the first step is to detect the 2D skeletal joints in the input image, followed by the step of 2D-to-3D lifting. We find that common lifting models fail when encountering a rotated input. We argue that learning a single human pose along with its in-plane rotations is considerably easier and more geometrically grounded than directly learning a point-to-point mapping. Furthermore, our intuition is that endowing the model with the notion of rotation equivariance without explicitly constraining its parameter space should lead to a more straightforward learning process than one with equivariance by design. Utilising the common HPE benchmarks, we confirm that the 2D rotation equivariance per se improves the model performance on human poses akin to rotations in the image plane, and can be efficiently and straightforwardly learned by augmentation, outperforming state-of-the-art equivariant-by-design methods.
Jan 20, 2026
Learning to Augment: Hallucinating Data for Domain Generalized Segmentation
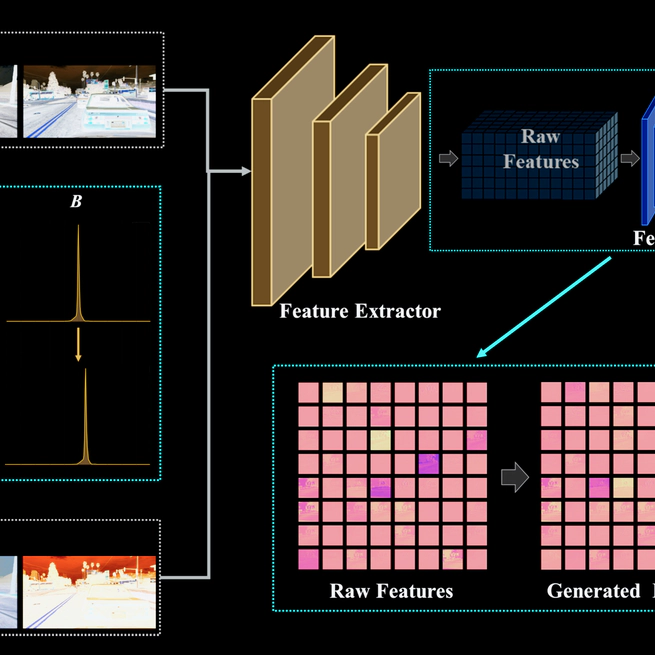
Domain generalized semantic segmentation (DGSS) is an essential but highly challenging task, in which the model is trained only on source data and any target data is not available. Existing DGSS methods primarily standardize the feature distribution or utilize extra domain data for augmentation. However, the former sacrifices valuable information and the latter introduces domain biases. Therefore, generating diverse-style source data without auxiliary data emerges as an attractive strategy. In light of this, we propose GAN-based feature augmentation (GBFA) that hallucinates stylized feature maps while preserving their semantic contents with a feature generator. The impressive generative capability of GANs enables GBFA to perform inter-channel and trainable feature synthesis in an end-to-end framework. To enable learning GBFA, we introduce random image color augmentation (RICA), which adds a diverse range of variations to source images during training. These augmented images are then passed through a feature extractor to obtain features tailored for GBFA training. Both GBFA and RICA operate exclusively within the source domain, eliminating the need for auxiliary datasets. We conduct extensive experiments, and the generalization results from the synthetic GTAV and SYNTHIA to the real Cityscapes, BDDS, and Mapillary datasets show that our method achieves state-of-the-art performance in DGSS.
Sep 12, 2023