Flow Matching for Probabilistic Monocular 3D Human Pose Estimation
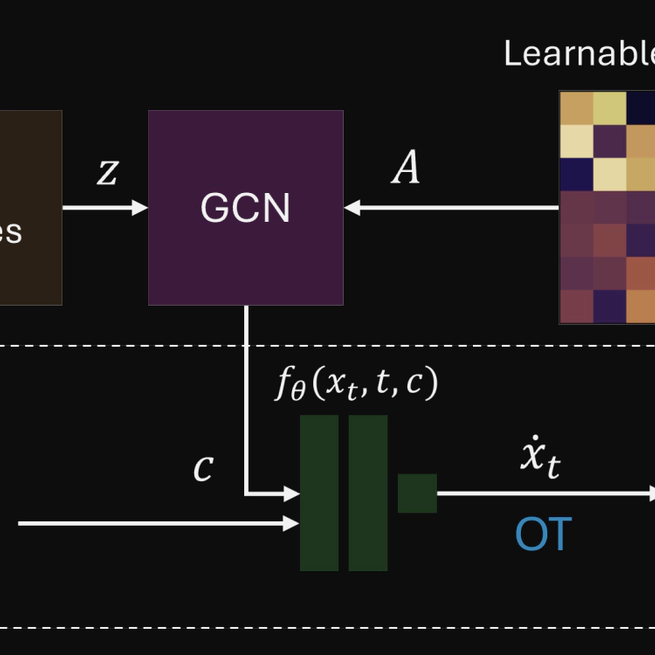
Recovering 3D human poses from a monocular camera view is a highly ill-posed problem due to the depth ambiguity. Earlier studies on 3D human pose lifting from 2D often contain incorrect-yet-overconfident 3D estimations. To mitigate the problem, emerging probabilistic approaches treat the 3D estimations as a distribution, taking into account the uncertainty measurement of the poses. Falling in a similar category, we proposed FMPose, a probabilistic 3D human pose estimation method based on the flow matching generative approach. Conditioned on the 2D cues, the flow matching scheme learns the optimal transport from a simple source distribution to the plausible 3D human pose distribution via continuous normalizing flows. The 2D lifting condition is modeled via graph convolutional networks, leveraging the learnable connections between human body joints as the graph structure for feature aggregation. While trade-offs between processing time and precision exist, already in the equal-accuracy comparison, FMPose exhibits significantly faster processing time than the diffusion model, and also offers another faster and more accurate configuration. Experimental results show major improvements of our FMPose over current state-of-the-art methods on two common benchmarks for 3D human pose estimation, namely Human3.6M, MPI-INF-3DHP. Additionally, FMPose shows competitive performance on the more challenging 3DPW dataset. The code implementation is available at https://github.com/cuongle1206/FMPose.
May 25, 2026
A High-Performance CNN Method for Offline Handwritten Chinese Character Recognition and Visualization
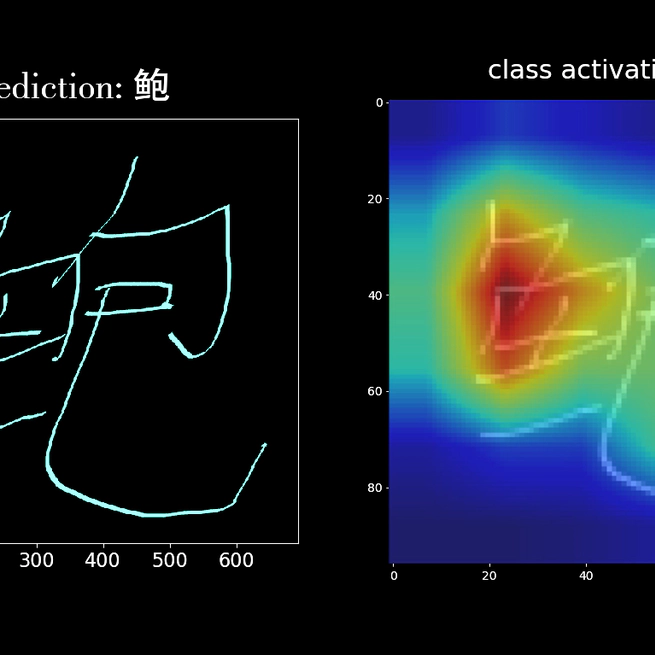
Recent researches introduced fast, compact and efficient convolutional neural networks (CNNs) for offline handwritten Chinese character recognition (HCCR). However, many of them did not address the problem of network interpretability. We propose a new architecture of a deep CNN with high recognition performance which is capable of learning deep features for visualization. A special characteristic of our model is the bottleneck layers which enable us to retain its expressiveness while reducing the number of multiply-accumulate operations and the required storage. We introduce a modification of global weighted average pooling (GWAP) - global weighted output average pooling (GWOAP). This paper demonstrates how they allow us to calculate class activation maps (CAMs) in order to indicate the most relevant input character image regions used by our CNN to identify a certain class. Evaluating on the ICDAR-2013 offline HCCR competition dataset, we show that our model enables a relative 0.83% error reduction while having 49% fewer parameters and the same computational cost compared to the current state-of-the-art single-network method trained only on handwritten data. Our solution outperforms even recent residual learning approaches.
May 30, 2020