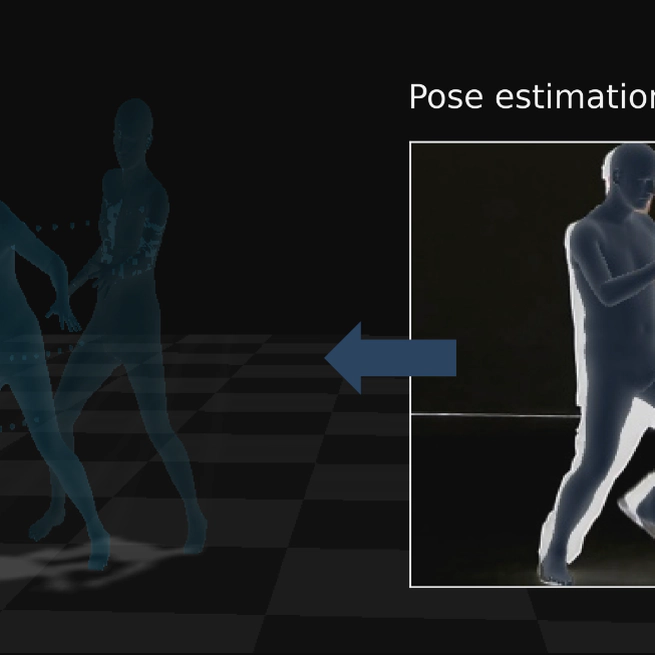
QuaMo: Quaternion Motions for Vision-based 3D Human Kinematics Capture
Vision-based 3D human motion capture from videos remains a challenge in computer vision. Traditional 3D pose estimation approaches often ignore the temporal consistency between frames, causing implausible and jittery motion. The emerging field of kinematics-based 3D motion capture addresses these issues by estimating the temporal transitioning between poses instead. A major drawback in current kinematics approaches is their reliance on Euler angles. Despite their simplicity, Euler angles suffer from discontinuity that leads to unstable motion reconstructions, especially in online settings where trajectory refinement is unavailable. Contrarily, quaternions have no discontinuity and can produce continuous transitions between poses. In this paper, we propose QuaMo, a novel Quaternion Motions method using quaternion differential equations (QDE) for human kinematics capture. We utilize the state-space model, an effective system for describing real-time kinematics estimations, with quaternion state and the QDE describing quaternion velocity. The corresponding angular acceleration are computed from a meta-PD controller with a novel acceleration enhancement that adaptively regulates the control signals as the human quickly change to new pose. Unlike previous work, our QDE is solved under the quaternion geometric constraints that results in more accurate estimations. Experimental results show that our novel formulation of the QDE with acceleration enhancement accurately estimates 3D human kinematics with no discontinuity and minimal implausible artifact. QuaMo outperforms comparable state-of-the-art methods on multiple datasets, namely Human3.6M, Fit3D, SportsPose and a subset of AIST. The code is available at https://github.com/cuongle1206/QuaMo.
Jan 26, 2026
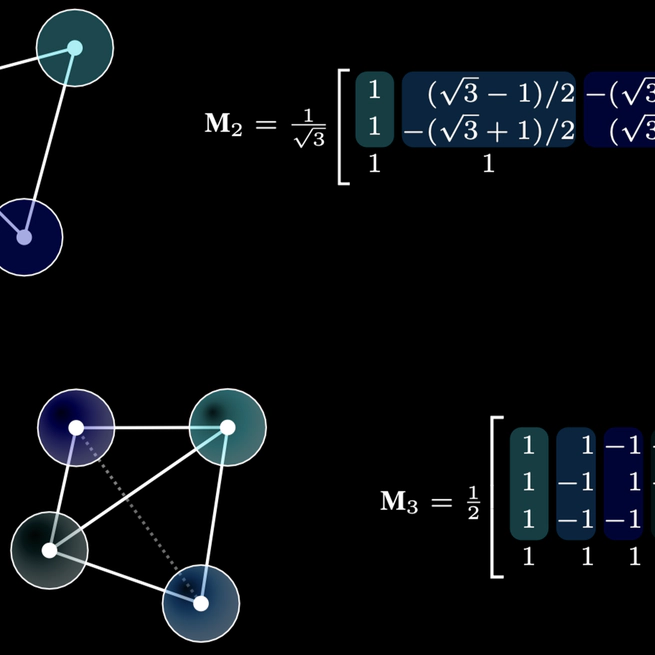
O$n$ Learning Deep O$(n)$-Equivariant Hyperspheres
In this paper, we utilize hyperspheres and regular $n$-simplexes and propose an approach to learning deep features equivariant under the transformations of $n$D reflections and rotations, encompassed by the powerful group of $\text{O}(n)$. Namely, we propose $\text{O}(n)$-equivariant neurons with spherical decision surfaces that generalize to any dimension $n$, which we call Deep Equivariant Hyperspheres. We demonstrate how to combine them in a network that directly operates on the basis of the input points and propose an invariant operator based on the relation between two points and a sphere, which as we show, turns out to be a Gram matrix. Using synthetic and real-world data in $n$D, we experimentally verify our theoretical contributions and find that our approach is superior to the competing methods for $\text{O}(n)$-equivariant benchmark datasets (classification and regression), demonstrating a favorable speed/performance trade-off.
Jul 22, 2024
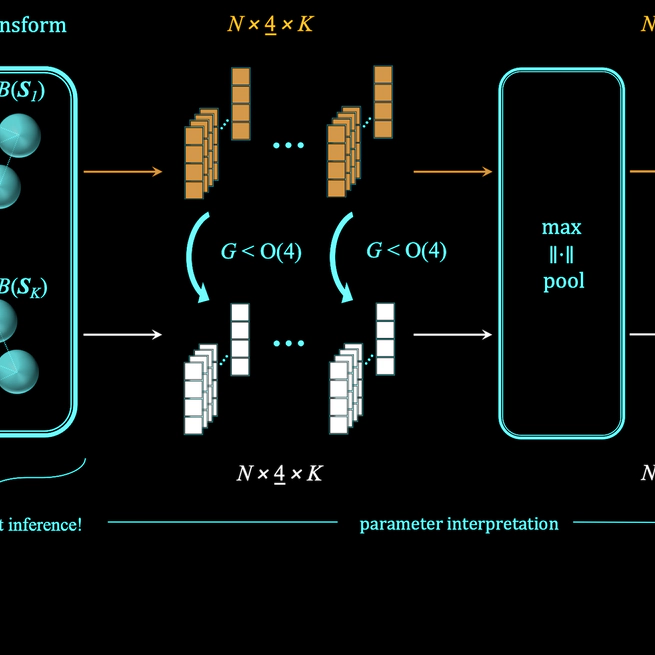
TetraSphere: A Neural Descriptor for O(3)-Invariant Point Cloud Analysis
In many practical applications 3D point cloud analysis requires rotation invariance. In this paper we present a learnable descriptor invariant under 3D rotations and reflections i.e. the O(3) actions utilizing the recently introduced steerable 3D spherical neurons and vector neurons. Specifically we propose an embedding of the 3D spherical neurons into 4D vector neurons which leverages end-to-end training of the model. In our approach we perform TetraTransform—an equivariant embedding of the 3D input into 4D constructed from the steerable neurons—and extract deeper O(3)-equivariant features using vector neurons. This integration of the TetraTransform into the VN-DGCNN framework termed TetraSphere negligibly increases the number of parameters by less than 0.0002%. TetraSphere sets a new state-of-the-art performance classifying randomly rotated real-world object scans of the challenging subsets of ScanObjectNN. Additionally TetraSphere outperforms all equivariant methods on randomly rotated synthetic data: classifying objects from ModelNet40 and segmenting parts of the ShapeNet shapes. Thus our results reveal the practical value of steerable 3D spherical neurons for learning in 3D Euclidean space.
Jun 17, 2024
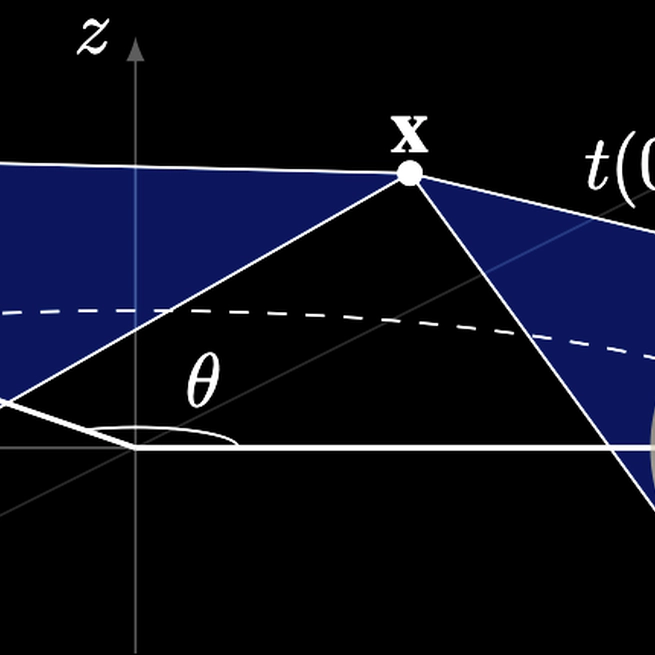
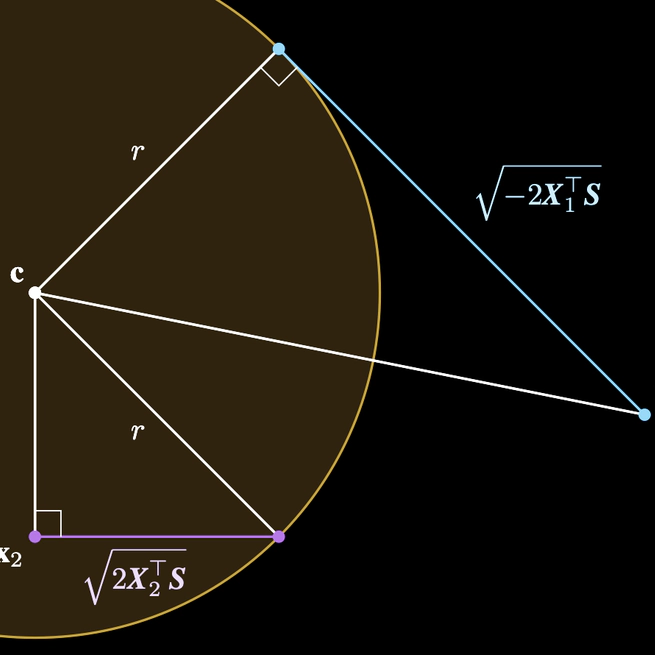
Steerable 3D Spherical Neurons
Emerging from low-level vision theory, steerable filters found their counterpart in prior work on steerable convolutional neural networks equivariant to rigid transformations. In our work, we propose a steerable feed-forward learning-based approach that consists of neurons with spherical decision surfaces and operates on point clouds. Such spherical neurons are obtained by conformal embedding of Euclidean space and have recently been revisited in the context of learning representations of point sets. Focusing on 3D geometry, we exploit the isometry property of spherical neurons and derive a 3D steerability constraint. After training spherical neurons to classify point clouds in a canonical orientation, we use a tetrahedron basis to quadruplicate the neurons and construct rotation-equivariant spherical filter banks. We then apply the derived constraint to interpolate the filter bank outputs and, thus, obtain a rotation-invariant network. Finally, we use a synthetic point set and real-world 3D skeleton data to verify our theoretical findings.
Jul 19, 2022
Embed Me If You Can: A Geometric Perceptron
Solving geometric tasks involving point clouds by using machine learning is a challenging problem. Standard feed-forward neural networks combine linear or, if the bias parameter is included, affine layers and activation functions. Their geometric modeling is limited, which motivated the prior work introducing the multilayer hypersphere perceptron (MLHP). Its constituent part, i.e., the hypersphere neuron, is obtained by applying a conformal embedding of Euclidean space. By virtue of Clifford algebra, it can be implemented as the Cartesian dot product of inputs and weights. If the embedding is applied in a manner consistent with the dimensionality of the input space geometry, the decision surfaces of the model units become combinations of hyperspheres and make the decision-making process geometrically interpretable for humans. Our extension of the MLHP model, the multilayer geometric perceptron (MLGP), and its respective layer units, i.e., geometric neurons, are consistent with the 3D geometry and provide a geometric handle of the learned coefficients. In particular, the geometric neuron activations are isometric in 3D, which is necessary for rotation and translation equivariance. When classifying the 3D Tetris shapes, we quantitatively show that our model requires no activation function in the hidden layers other than the embedding to outperform the vanilla multilayer perceptron. In the presence of noise in the data, our model is also superior to the MLHP.
Sep 21, 2021